Индексирование в базах данных
Структура хранения на основе индексирования предполагает использовать двух хранимых файлов.
1. Файл таблицы с данными (например, поставщиков деталей), его условно называют последовательный файл.
2. Файл с индексами (например, данные о городах проживания поставщиков).
В файле с индексами названия городов всегда упорядочены по алфавиту. И фактически есть риды (RID) соответствующие записи файла поставщиков.
Например:
Представим себе файл с данными, т.е таблица с поставщиками, там есть определенное количество записей. Риды S1,S2 и так далее.
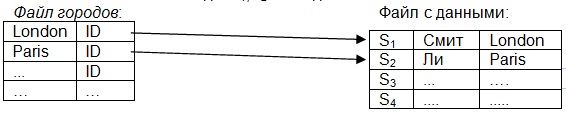
В индексном файле записи упорядочены по алфавиту, а в файле с данными записи располагаются как есть.Они могут быть упорядоченны не по файлу городов, а по номеру или фамилии поставщика. Но нам допустим надо по городу. Файл городов в этом случае называется индексным файлом, состоящим из двух колонок. Ну а файл таблица (в физическом смысле файл, или в логическом смысле файл, как это в SQL серверах) называется индексированным .
Фактически для того чтобы найти сведения быстро в таблице, первоначально считывается индексный файл, он поскольку всегда состоит из двух колонок, то он может быть относительно малым (а таблица может быть достаточно широкой). Загружается в память (индексный файл). Так как записи упорядочены по алфавиту, то быстро находиться по алфавиту методом двоичного поиска( он быстрый). Когда у нас данные индексированы от маленького значения до большого, фактически первый раз ищется половина, смотрим попали или не попали. Если не попали, то следующую пополам, если не попали опять следующую и так далее. Всего надо 10 шагов чтобы в файле из 1024 записей в порядке возрастания, или убывания найти нужную запись. Если бы искали по порядку то в худшем случае оказалось бы 1024 поиска. Скорость поиска по индексному файлу очень велика, и чем больше записей тем быстрее, вместо последовательного поиска по всем записям нужной записи.
Иногда индексный файл называют инвертированным списком. Очень удобны такие инвертированные списки когда они делаются по ключевому полю, по Primary Key. Очень эффективны и быстро работают. В принципе могут быть две стратегии поиска поставщиков ,например, из города London. В файле поставщиков найти все записи, названия городов которых являются London.Или сначала в файле городов найти все значения с London, а затем по указателям найти записи. Во втором случае получается гораздо быстрее. Правда есть время, затрачиваемое на считывание файла городов. Если эти файлы соизмеримы то выигрыша нет, для маленьких табличек до 300 записей смысла индексы делать нет, потому что таблица с малым числом строк всегда загружается в виде страницы в память и что по индексу искать, что искать по памяти одинаково.
Если доля поставщиков из London очень мала, то такой файл эффективен (индексированный файл), если их доля велика то этот файл будет часто включаться, тогда выигрыш от использования индексного файла начинает теряться. Индексы всегда хороши когда число искомых записей не превышает 10-15 процентов. Когда число искомых записей от 20% и выше то можно искать по прямому поиску.
Все записи про London идут друг за другом, и если нашлись несколько записей, идущих подряд, то ясно их положение, здесь они быстро считываются, и эти идентификаторы указывают на нужные записи. Если бы мы не упорядочивали, то London может встречаться где угодно и поиск будет долгим. Нужно будет просматривать всю таблицу.
Таким образом индексы позволяют избежать полного просмотра таблиц, который снижает существенно производительность. Снижает производительность не только конкретного клиента, который смотрит и перебирает всю таблицу, но и других, т.к сеть перегружается, буфер у сервера тоже перегружается, т.е тратятся у системы большие ресурсы и другие клиенты не могут их использовать. Сервер часто считывает данные, запись за записью диск только работает на одного человека.
Недостатки индексирования
Недостаток использования индексов заключается в том, что если их много, то после обновления данных в таблицах(просто обновления, удаления, добавления записей) индексы должны перестраиваться. Чем больше индексов, тем больше перестроек. В руководстве SQL сервер говориться так : “на одну таблицу не более 16 индексов”. После 16 быстродействие не гарантируется, т.е до 16 индексов переиндексацию сервер обеспечивает относительно быстро, а дальше производительность сильно падает.
Если индексирование сделано по первичному ключу. То индекс называется первичным. В противном случае он называется вторичным, если по всем другим колонкам, например, по городам, по каким нибудь рейтингам, и т.д. Если индекс сделан по первичному ключу, то он еще в дополнение называется уникальным, потому что повторяющихся значений по первичному ключу в принципе быть не может. В файле городов он не может быть уникальным, т.к городов проживания может быть много (у многих клиентов могут быть одинаковые города).
Индексы могут использоваться для двух целей:
1) для последовательного доступа. Например, найти всех поставщиков из города London.
2) Для прямого доступа. Когда надо найти что-то конкретное.