Многоуровневые индексы, вторичные индексы, поиск документов и обращенные индексы
Многоуровневые индексы
Для ускорения просмотра больших индексов, часто делают индекс для индекса. Тогда индексный файл очень большой, и его приходиться частями загружать в оперативную память, и это тоже долго. Тогда если есть индексный файл, то фактически делается другой уровень.
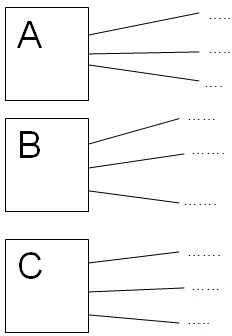
Как только мы смотрим по символьному полю, или по числовому, более понятно на символьном поле. Допустим на A, B, C города, но все города на A (букву А) для них нужно считать не весь этот индекс, а только его часть. Т.е сначала считать индекс A потом, страницу городами на А.
Индекс для индекса позволяет ускорить процесс поиска, и в этом случае такой индекс называют многоуровневым. Индексов на индекс можно делать достаточно много, но обычно больше 3 ярусов не делают.
Вторичные индексы
1) Часто для повышения быстродействия выборки данных, приходиться создавать несколько индексов для одной таблицы, большинство из которых является вторичными.( поскольку уникальный-один, остальные все вторичные).Фактически вторичный индекс выполняет те же самые функции что и первичный(он используется для поиска данных). Отличается от первого тем, что не может предсказать расположение данных. (например когда мы говорили в примере неплотного индекса, что они индексируют страницу, а страница упорядочена, и понятно где будет следующий индекс). Поэтому вторичные индексы не могут предсказать расположение подряд городов(если упорядочение идет по номерам), или например рейтинг, или фамилию поставщика( так как данные расположены неупорядоченно).
Т.е первичный индекс помимо того что позволяет искать, может предсказать где расположена следующая запись, вторичные этого делать не могут.
2) Вторичные индексы часто бывают сдублены. Первичный индекс делается по Primary Key, по номеру, номера как правило должны быть уникальными, и там используются все записи, а по вторичному индексу(например по файлу городов) там могут быть дубли, городов всегда меньше, чем людей которые там проживают.
Формально можно использовать многоуровневые вторичные индексы, в этом случае часто на втором уровне могут попадаться дубликаты.
Поиск документов и обращенные индексы
Для поиска документов среди WEB используются обращенные индексы. По существу это индексы, состоящие из большого числа полей, т.е по одному булевому значению для каждого слова, и когда тот или иной Yandex, Google, Yahoo и тд ищут они просматривают таблицы( первоначально для них составляются таблицы, где галочками отмечается если то что нужно или нет на определенной веб странице) по этим индексам, и смотрят есть ли галочки или нет, и эти страницы считывают.
Поэтому чем больше сайтов проиндексировано, тем эта таблица длиннее и шире(больше слов используется). Т.е таблицы огромные, они просматриваются и ставятся булевые галочки, есть это слово(которое ищем) или нет.
Поэтому те поисковые системы, которые проиндексируют больше сайтов, у них таблица по длине и ширине больше.
Таким образом получают обращенные индексы.